이 글은 나동빈님의 'Transformer : Attention Is All You Need' 논문 리뷰 영상을 보고 정리한 글입니다.
자연어처리 중에서도 핵심인 기계번역을 주로 살펴보면,
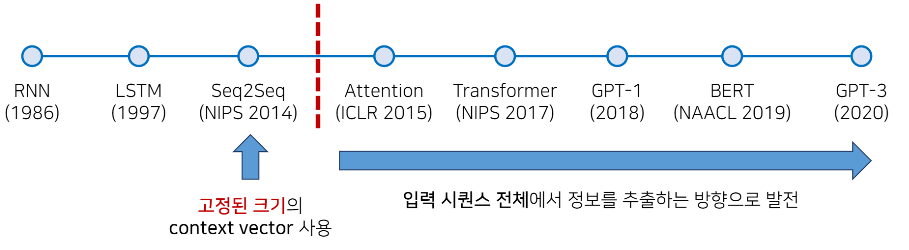
RNN (1986) : RNN 첫 시작. 10년 후 LSTM
LSTM (1997) : 다양한 시퀀스 정보 모델링 가능 - 주가예측, 주기함수 예측
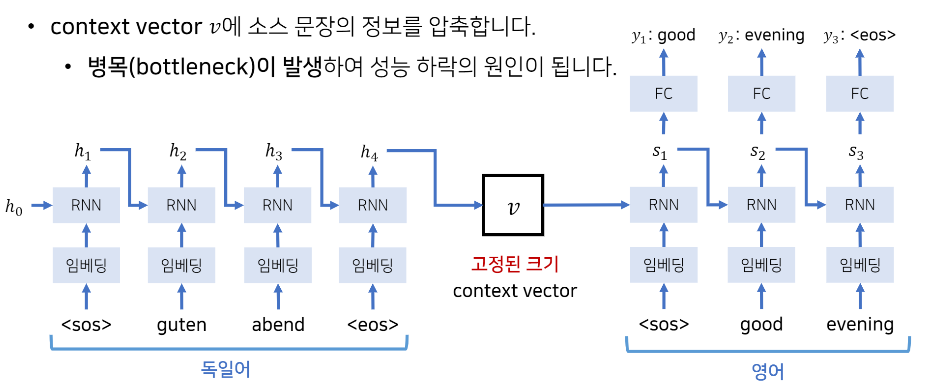
Seq2Seq (NIPS 2014)LSTM 활용해서 딥러닝 기반 기술로 탄생. 현대의 딥러닝 기술들이 나오던 시점에 탄생. LSTM 을 활용해서 고정된 크기의 context vector 를 사용하는 방식으로 번역 수행. 따라서 소스 문장을 전부 고정된 크기의 한 벡터에 압축해야 하는 가 존재했음
성능적인 한계
Attention (ICLR 2015) : Seq2Seq 모델에 어텐션 기법 적용하여 성능 더 올릴 수 있었음
Transformer (NIPS 2017)아예 RNN 자체를 사용할 필요가 없다고 제안. 오직 어텐션 기법에 의존하는 아키텍쳐를 설계했더니 성능이 엄청 향상. 트랜스포머를 기점으로 자연어 처리 기법으로 RNN 더이상 사용하지 않고 어텐션 메커니즘을 더욱 더 많이 사용어텐션 메커니즘 등장 이후 입력 시퀀스 전체에서 정보를 추출하는 방향으로 연구 방향 발전. 어텐션 기법을 활용하는 트랜스포머 아키텍쳐를 따르는 방식으로 다양한 고성능 모델들이 제안되고 있음.